A Bit of History
Pyramid building, tax collection, and war waging are not exactly simple enterprises. So complex are these operations, that their management requires a great technology. A technology so transformational, our modern Ops stacks pale in comparison. I speak, of course, of the technology of writing.
Writing first appeared over 5,000 years ago in the ancient Mesopotamian civilization of Sumer. The invention of writing was so closely coincident with that of bookkeeping, auditing, and other administrative practices that it is reasonable to say it was invented for the purpose of bookkeeping[1],[2]. In fact, roughly 90 percent of surviving ancient Sumerian tablets served administrative purposes[3]. Sumerian scribes kept detailed records of a vast array of transactions – no matter how big or small. Examples range from “a barge full of grain to a dead fowl”[4].
![Example of a Sumerian tablet summarizing account of silver[5].](cuneiform.png)
Why would a society go through so much trouble? What is the administrative value of good record-keeping? Fundamentally, record-keeping in the 4th millennium BC and in modernity provides the same value: to be able to reason about the past so that better decisions can be made in the future. All good Ops2 must keep this as a primary objective.
2 MLOps, DevOps, PyramidOps, TaxOps, WarOps, CyclOps, LollipOps, FlipflOps, TriceratOps, BarbershOps, MuttonchOps, MountaintOps, ArchbishOps, etc…
Why Automate?
For many, MLOps3 is synonymous with automation. This is like equating carpentry with the use of power tools. Yes, power tools offer incredible utility to the craft of carpentry, but carpentry is so much more than the use of a table saw. Similarly, automation is an incredible tool for MLOps, but it is not an end unto itself.
3 and the earlier coined “DevOps”
In further error, the utility of automation is too often limited to “doing things faster”. All else being equal, speeding up a process is worthwhile, but it is hardly the only objective worth optimizing for. Well-crafted automations lead to improvements in
- reliability
- repeatability
- auditability
- and yes… “doing things faster”
The following famous xkcd comic is still a good rule of thumb, but only if you interpret “How Much Time You Shave Off” more broadly.
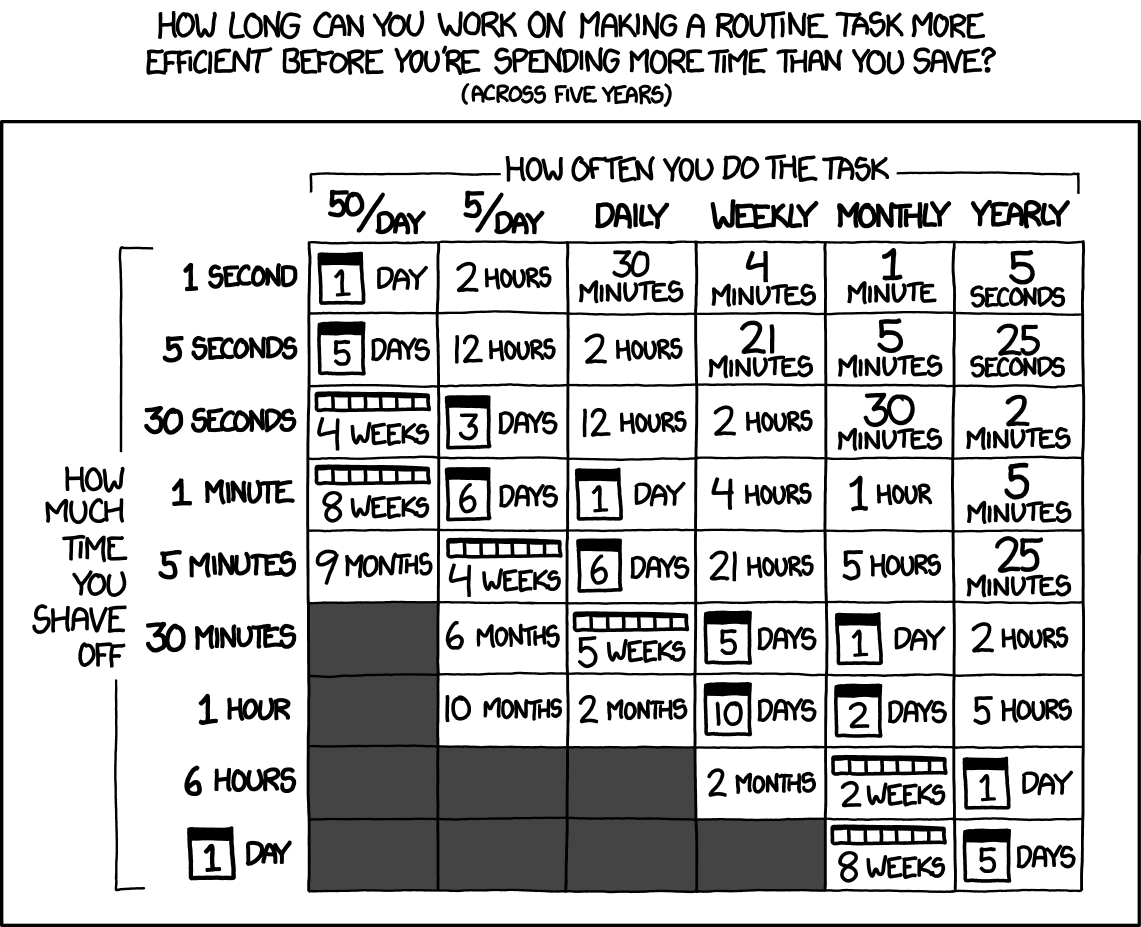
Here are some examples of hidden time savings:
- After a benchmark, the resulting report is automatically stored in a standard location
- Congratulations! You no longer need to ping your colleague on Slack to ask where they put that report.
- Before training a model, the information about input datasets is automatically stored
- Congratulations! In three weeks, when you realize your model is doing ‘suspiciously well’ on a specific subset of the benchmark set, you can check for data leakage without needing to retrain your model.
- Before training a model, the computational environment used for training is automatically stored
- Congratulations! When you need to retrain this model in six weeks, you don’t need to spend time remembering exactly which magic combination of shell commands and software versions are required to get things running again.
{kind=link}